Business Agenda:
This investigation into the realm of Data Scientist positions on Glassdoor assisted me in better understanding the landscape of the job market. However, as some companies are reluctant to list salaries for positions, I created a model that estimates the salary of a job opportunity based on some company and position factors. It helped to reinforce preconceived notions I had regarding a shift into Python being the dominant required language for Data Scientist positions. My model takes into account a number of various factors about the job and the company making the posting and predicts with fairly high accuracy (MAE of 11K) the salary of the position. The availability of jobs in the IT and Business sectors is excellent as these are the fields highlights the technical ability required in landing a Data Scientist position. Overall I am satisfied with the results of the model and it provides an elegant solution to the issue of some hidden salary positions.
Overview: Created a Project to estimate salaries (MAE around $11K) on Data Scientist Jobs to help understand the workspace landscape.
- Scraped about 1000 jobs from Glassdoor utilizing selenium and python
- Created features from the job description to help understand the value companies place on python and excel
- Optimized Lasso, Random Forest and Gradient Boosting Regressor using GridsSearch CV
- Created Client facing API using Flask
Web Scraping:Scraped the following:
- Job Title
- Salary Estimate
- Job Description
- Rating
- Company Name
- Location
- Headquarters
- Size
- Founded
- Type of ownership
- Industry
- Sector
- Revenue
- Competitors
Data Cleaning and Feature Engineering:After scraping the data I needed to clean it up for use in the model. I made the following changes:
- Parsed numeric data out of salary
- Created columns for hourly wages and employer provided salary
- Parsed rating out of company name
- Changed foundation date into age of company
- Created columns if the following skills were in the job description:
- Python
- R
- Excel
- Created Column for Simplified Job Title
- Created Columns for Seniority if it was listed in the Job Title
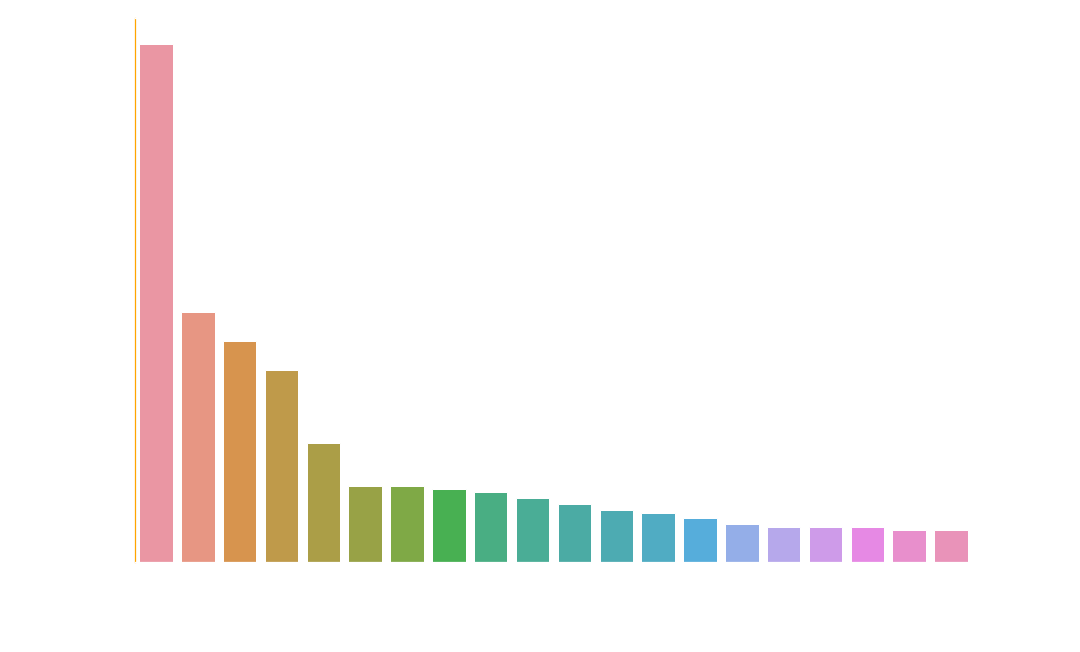 From this chart we see that California leads the way in terms of available jobs with Massachusetts coming up second.
Luckily my state of NY is fourth on the list so there are plenty of data scientist jobs still available.
From this chart we see that California leads the way in terms of available jobs with Massachusetts coming up second.
Luckily my state of NY is fourth on the list so there are plenty of data scientist jobs still available.
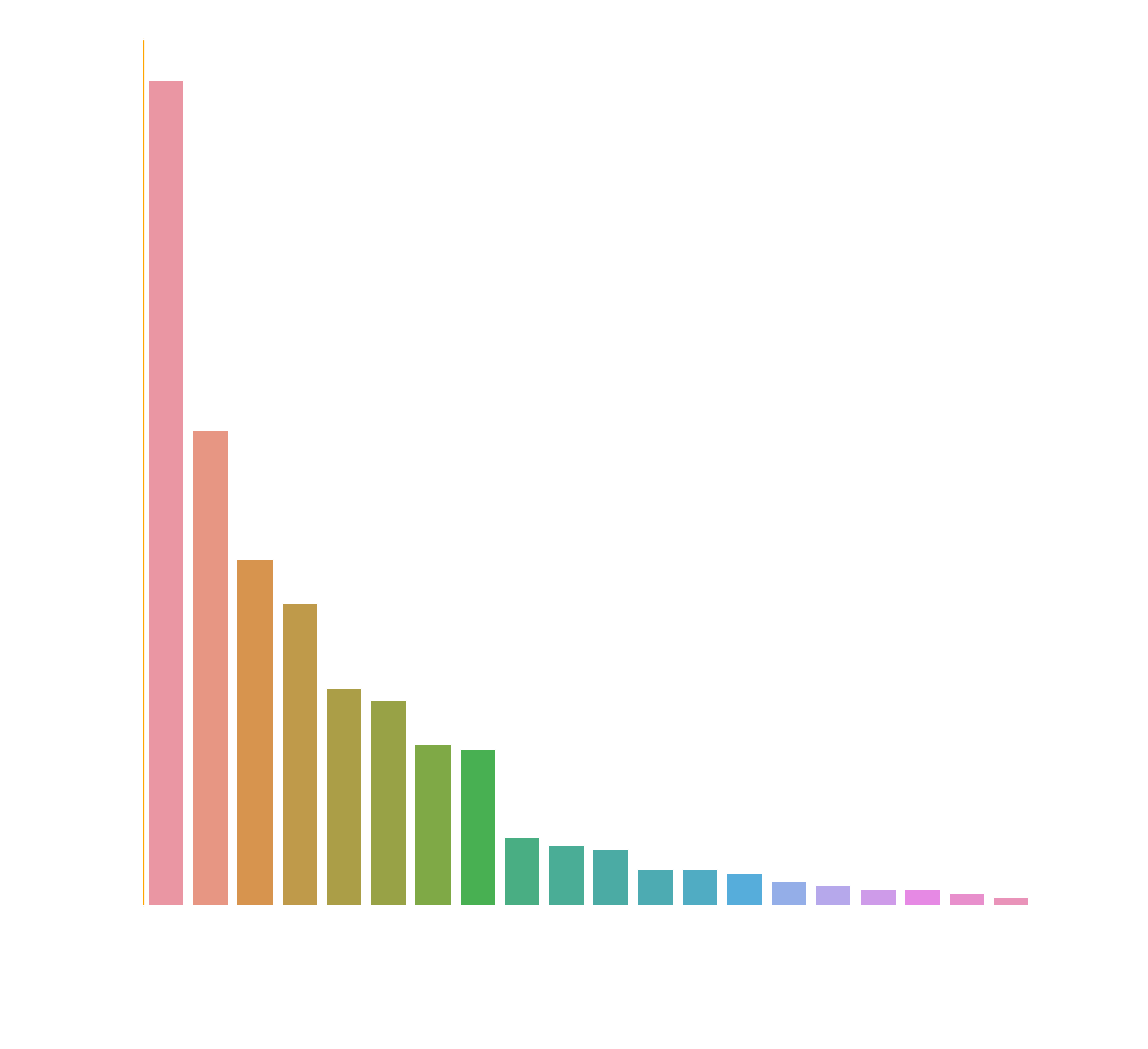 From this chart we see that IT sector leads the way in terms of available jobs, with Business Services coming up second.
From this chart we see that IT sector leads the way in terms of available jobs, with Business Services coming up second.
Model Building: First, I transformed the categorical variables into dummy variables. Then I split the data into train and test sets with a test set of 30%. I tried out three different models and evaluated their performance based on Mean Absolute Error. I chose MAE because of the ease of interpretation and since it stands up to outliers fairly well.
Model Performance:The Random Forest Model proved to be the most effective and outperformed the other approaches on both the training and validation sets: (Model and Error)
- Lasso Regression = $17.73 K
- Random Forest = $10.58 K
- Gradient Boosting = $14.61 K
- Category: Data Visualization and Regression
- Date: July 2020
- Github: View on Github